TCP Socket的粘包和分包的处理
概述
在进行TCP socket开发时,都需要处理数据包粘包和分包的情况。解决方法在应用层下,定义一个协议:消息头部+消息长度+消息正文即可。
只有TCP有粘包问题,而UDP永远不会粘包。socket收发消息原理:
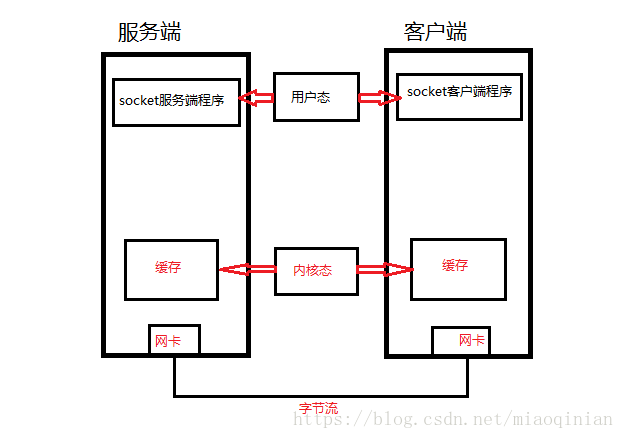
服务端可以1kb,1kb的向客户端发送数据,客户端的应用程序可以在缓存当中2kb,2kb地取走数据,当然也可以更多,或更少。也就是说,应用程序看到的数据是个整体。或者说是一个流。一条消息有多少个字节对应用程序是可见的,tcp协议是面向流的协议,这就是它容易粘包的问题原因。
所谓粘包问题主要还是因为接收方不知道消息之间的界限,不知道一个消息要提取多少字节的数据所造成的。
此外,发送方引起的粘包是由tcp协议本身造成的,tcp为提高传输效率,发送方往往收集到足够多的数据才发送一个tcp段。若连续几次需要发送的数据都很少,通常tcp会根据nagle优化算法 ,把这些数据合成一个tcp段后发送出去,这样接收方就收到了粘包数据。
粘包情况一:发送端要等缓冲区满才发送出去(即发送的数量少且时间间隔短,会合并到一起),造成粘包
1、服务端
1 | from socket import * |
2、客户端
1 | from socket import * |
先启动服务端,后再启动客户端,服务端得到的结果为:
1 | [root@seafile:~]# python3 server.py |
可以看出客户端是发了两次数据而服务端一次就接收完了。
粘包情况二:客户端发送了一段数据,服务端只收了一小部分,服务端下次再收的时候是从缓冲区拿上次遗留的数据,产生粘包。
情况一的,客户端不变,服务端略作修改,如下:
1 | from socket import * |
先启动服务端,后再启动客户端,服务端得到的结果为:
1 | [root@seafile:~]# python3 server.py |
现在我们来想一下如何处理粘包的方法。粘包的问题根源是接收端不知发送端将要传送的字节流,所以我们要让发送端在发送数据前,把要发送的字节流总大小让接收端知晓,然后接收端来个循环将其全部接收。这种方法比较低级,存在的问题:程序的运行速度远快于网络传输速度,所以在发送一段字节前,先用send去发送该字节流长度,这种方式会放大网络延迟带来的性能损耗
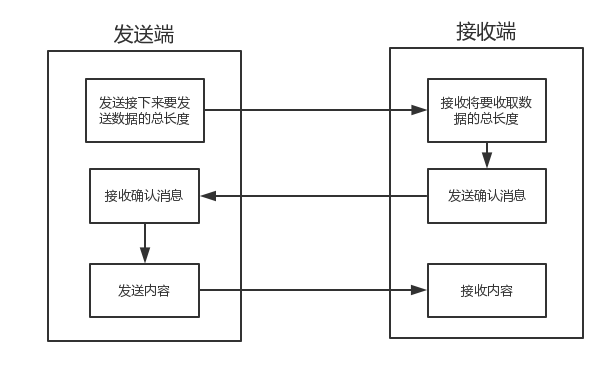
程序的运行速度远快于网络传输速度,所以在发送一段字节前,先用send去发送该字节流长度,这种方式会放大网络延迟带来的性能损耗
刚才上面 在发送消息之前需先发送消息长度给对端,还必须要等对端返回一个ready收消息的确认,不等到对端确认就直接发消息的话,还是会产生粘包问题(承载消息长度的那条消息和消息本身粘在一起)。 有没有优化的好办法么?
思考一个问题,为什么不能在发送了消息长度(称为消息头head吧)给对端后,立刻发消息内容(称为body吧),是因为怕head 和body 粘在一起,所以通过等对端返回确认来把两条消息中断开。
可不可以直接发head + body,但又能让对端区分出哪个是head,哪个是body呢?我靠、我靠,感觉智商要涨了。
想到了,把head设置成定长的呀,这样对端只要收消息时,先固定收定长的数据,head里写好,后面还有多少是属于这条消息的数据,然后直接写个循环收下来不就完了嘛!唉呀妈呀,我真机智。
可是、可是如何制作定长的消息头呢?假设你有2条消息要发送,第一条消息长度是 3000个字节,第2条消息是200字节。如果消息头只包含消息长度的话,那两个消息的消息头分别是
1 | len(msg1) = 4000 = 4字节 len(msg2) = 200 = 3字节 |
你的服务端如何完整的收到这个消息头呢?是recv(3)还是recv(4)服务器端怎么知道?
目前比较合理的处理方法是:为字节流加上一个报头,将这个报头做成字典,字典里包含将要发送的真实数据详细信息。将这个字典JSON序列化,然后用struck将序列化后的数据长度打包成4个字节(4个字节完全够用)
发送时:先发报头长度,再编码报头内容后发送,最后发真实数据。
接收时:用struct取出报头长度,然后根据长度取出报头,解码,反序列化。最后从反序列化的结果中取出待取数据的详细信息,然后取真实的数据内容。
来看实现的代码:
1、服务端
1 | from socket import * |
2、客户端
1 | from socket import * |
补充struct模块:
1 | import struct |
原文链接:https://blog.csdn.net/miaoqinian/article/details/80020291