线程与进程
一、线程介绍
线程是操作系统能够进行运算调试的最小单位,它被包含在进程之中,是进程中的实际运行单位,一条线程指的是一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。
在同一个进程内的线程的数据可以进行互相访问的。
线程的切换使用过上下文来实现的,比如有一本书,有a和b这两个人(两个线程)看,a看完之后记录当前看到那一页哪一行,然后交给b看,b看完之后记录当前看到了那一页哪一行,此时a又要看了,那么a就通过上次记录的值(上下文)直接找到上次看到了哪里,然后继续往下看。
线程中的5种状态:
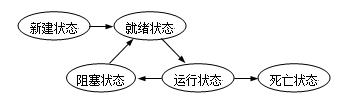
各状态说明:
1.新建状态 (New)
使用threading.threading创建实例时候,线程还没有开始运行,此时线程处在新建状态。 当一个线程处于新生状态时,程序还没有开始运行线程中的代码。
2.就绪状态(Runnable)
一个新创建的线程并不自动开始运行,要执行线程,必须调用线程的start()方法。当线程对象调用start()方法即启动了线程,start()方法创建线程运行的系统资源,并调度线程运行run()方法。当start()方法返回后,线程就处于就绪状态。
处于就绪状态的线程并不一定立即运行run()方法,线程还必须同其他线程竞争CPU时间,只有获得CPU时间才可以运行线程。因为在单CPU的计算机系统中,不可能同时运行多个线程,一个时刻仅有一个线程处于运行状态。因此此时可能有多个线程处于就绪状态。
3.运行状态(Running)
当线程获得CPU时间后,它才进入运行状态,真正开始执行run()方法.
4.阻塞状态(Blocked)
线程运行过程中,可能由于各种原因进入阻塞状态:
1>线程通过调用sleep方法进入睡眠状态;
2>线程调用一个在I/O上被阻塞的操作,即该操作在输入输出操作完成之前不会返回到它的调用者;
3>线程试图得到一个锁,而该锁正被其他线程持有;
4>线程在等待某个触发条件;
……
所谓阻塞状态是正在运行的线程没有运行结束,暂时让出CPU,这时其他处于就绪状态的线程就可以获得CPU时间,进入运行状态。
5.死亡状态(Dead)
有两个原因会导致线程死亡:
1) run方法正常退出而自然死亡,
2) 一个未捕获的异常终止了run方法而使线程猝死。
为了确定线程在当前是否存活着(就是要么是可运行的,要么是被阻塞了),需要使用isAlive方法。如果是可运行或被阻塞,这个方法返回true,如果线程仍旧是new状态且不是可运行的, 或者线程死亡了,则返回false.
python中的多线程:
python通过两个标准库thread和threading提供对线程的支持。thread提供了低级别的、原始的线程以及一个简单的锁、threading则弥补了其缺陷,所以线程模块使用threading就可以了。
多线程在python内实则就是一个假象,为什么这么说呢,因为cpu的处理速度是很快的,所以我们看起来以一个线程在执行多个任务,每个任务的执行的速度是非常之快的,利用上下文切换来快速的切换任务,以至于我们根本感觉不到时。
但是频繁的使用上下文切换也是要耗费一定的资源,因为单线程在每次切换任务的时候需要保存当前任务的上下文。
什么时候用到多线程?
首先IO操作是不占用cpu的,只有计算的时候才会占用cpu(譬如1+1=2),python中的多线程不适合cpu密集型的任务,适合IO密集型的任务(socket server)。
IO密集型(I/O bound):频繁网络传输、读取硬盘及其他IO设备称之为IO密集型,最简单的就是硬盘存取数据,IO操作并不会涉及到cpu。
计算密集型(cpu bound):程序大部分在做计算、逻辑判断、循环导致cpu占用率很高的情况,称之为计算密集型,比如说python程序中执行了一段代码1+1,这就是在计算1+1的值。
线程创建方法:
1.普通方法
1 | #!/usr/bin/env python3 |
2.类继承方法
1 | #!/usr/bin/env python3 |
threading模块提供方法:
- start 线程准备就绪,等待CPU调度
- setName 为线程设置名称
- getName 获取线程名称
- setDaemon 设置为守护线程(在start之前),默认为前台线程,设置为守护线程以后,如果主线程退出,守护线程无论执行完毕都会退出
- join 等待线程执行结果,逐个执行每个线程,执行完毕后继续往下执行,该方法使得多线程变得无意义
- run 线程被cpu调度后自动执行线程对象的run方法
- isAlive 判断线程是否活跃
- threading.active_count 返回当前活跃的线程数量
- threading.current_thread 获取当前线程对象
使用list主线程阻塞,子线程并行执行demo:
1 | #!/usr/bin/env python3 |
这样的好处在于,在启动线程后统一join,缩短了程序运行时间,并且提高运行效率。
关于python的GIL(Global Interpreter Lock)
首先需要明确的一点是GIL并不是python的特性,它是在实现python解析器(cpython)时所引入的一个概念。就好比C++是一套语言(语法)标准,但是可以用不同的编译器来编译成可执行代码 ,有名的导航器例如GCC,INTEL C++,Visual C++等,python也一样,同样一段代码可以通过CPython,pypy,psyco等不同的python执行环境来执行。像其中的JPython就没有GIL。然而因为Cpython是大部分环境下默认的python执行环境,所以在很多人的概念里Cpython就是pypthon,也就想当然的把GIL归结为Python语言的缺陷。所以这里要先明确一点:GIL并不是python的特性,python完全可以不依赖于GIL。
Python GIL其实是功能和性能之间权衡后的产物,它尤其存在的合理性,也有较难改变的客观因素,无论你启多少个线程,你有多少个cpu,Python在执行的时候在同一时刻只允许一个线程运行。
线程锁(互斥锁Mutex)
一个进程下可以启动多个线程,多个线程共享父进程的内存空间,也就意味着每个线程可以访问同一份数据,此时,如果2个线程同时要修改同一份数据,会出现什么状况?
1 | import threading |
上述结果并不是我们想要的,去掉了sleep结果才是我们想要的,若是不去掉sleep呢,该怎么办?,此时我们可以加锁实现。
1 | import threading |
RLock(递归锁)
递归锁,通俗来讲就是大锁里面再加小锁,有人可能会问,那我使用Lock不就完了吗,其实不然,想象一下,现在有两道门,一把锁对应一把钥匙,如果使用Lock,进去第一个门获取一把锁,在进去第二个人门又获取一把锁,然后要出来开锁时候(释放锁)程序还是用第一个门进来的钥匙,此时就会一直阻塞,那么RLock就解决了这样的问题场景。
1 | import threading |
Semaphore&BoundedSemaphore(信号量)
前面已经介绍过了互斥锁, 互斥锁同时只允许一个线程更改数据,而Semaphore是同时允许一定数量的线程更改数据 ,比如厕所有3个坑,那最多只允许3个人上厕所,后面的人只能等里面有人出来了才能再进去.
1.Semaphore和BoundedSemaphore使用方法一致
方法:
- acquire(blocking=True,timeout=None)
- release()
1 | import threading |
Events
Event是线程间通信最间的机制之一:一个线程发送一个event信号,其他的线程则等待这个信号。用于主线程控制其他线程的执行。 Events 维护着一个flag,这个flag可以使用set()设置成True或者使用clear()重置为False,flag默认为False,而当flag为false时候,wait(timeout=s)则阻塞。
常用方法:
- Event.set():将标志设置为True
- Event.clear():清空标志位,设置为False
- Event.wait(timeout=s):等待(阻塞),直到标志位变成True
- Event.isSet():判断标志位是否被设置
1 | import threading,time |
Timer(定时器)
Timer用来定时执行某个线程,若取消运行,则使用cancel方法。

1 | import threading |
线程池:
启动一个线程消耗的资源非常少,所以对线程的使用官方并没有给出标准的线程池模块,第三方模块(Threadpool),下面我们自己定义简单线程池。
1 | import threading |
二、进程介绍
一个进程至少要包含一个线程,每个进程在启动的时候就会自动的启动一个线程,进程里面的第一个线程就是主线程,每次在进程内创建的子线程都是由主线程进程创建和销毁,子线程也可以由主线程创建出来的线程创建和销毁线程。
进程是对各种资源管理的集合,比如要调用内存、CPU、网卡、声卡等,进程要操作上述的硬件之前都必须要创建一个线程,进程里面可以包含多个线程,QQ就是一个进程。
继续拿QQ来说,比如我现在打卡了QQ的聊天窗口、个人信息窗口、设置窗口等,那么每一个打开的窗口都是一个线程,他们都在执行不同的任务,比如聊天窗口这个线程可以和好友进行互动,聊天,视频等,个人信息窗口我可以查看、修改自己的资料。
为了进程安全起见,所以两个进程之间的数据是不能够互相访问的(默认情况下),比如自己写了一个应用程序,然后让别人运行起来,那么我的这个程序就可以访问用户启动的其他应用,我可以通过我自己的程序去访问QQ,然后拿到一些聊天记录等比较隐秘的信息,那么这个时候就不安全了,所以说进程与进程之间的数据是不可以互相访问的,而且每一个进程的内存是独立的。
多进程
多进程的资源是独立的,不可以互相访问,如果想多个进程之间实现数据交互就必须通过中间件实现。
启动一个进程方法与启动一个线程类似
1 | #!/usr/bin/env python3 |
在进程中启动线程:
1 | #!/usr/bin/env python3 |
进程间通信方法(Queue、Pipes、Mangers)
前面已经提到,进程间通信是需要中间件来实现的,下面介绍几个实现进程间通信的中间件。
1.进程Queue:建立一个共享的队列(其实并不是共享的,实际是克隆的,内部维护着数据的共享),多个进程可以向队列里存/取数据。
1 | #!/usr/bin/env python3 |
2.Pipes(管道)
正如其名,进程间的管道内部机制通过启动socket连接来维护两个进程间的通讯。
1 | from multiprocessing import Process,Pipe |
3.Manager(数据共享)
Manager实现了多个进程间的数据共享,支持的数据类型有 list, dict, Namespace, Lock, RLock, Semaphore, BoundedSemaphore, Condition, Event, Barrier, Queue, Value and Array。
1 | from multiprocessing import Manager,Process |
进程锁(Lock)
进程锁和线程锁使用语法上完全一致。
1 | from multiprocessing import Process,Lock |
pool(进程池)
进程池内部维护一个进程序列,当使用时,则去进程池中获取一个进程,如果进程池序列中没有可供使用的进进程,那么程序就会等待,直到进程池中有可用进程为止。
主要方法:
- apply :该方法启动进程为串行执行
- apply_async:启动进程为并行执行
1 | from multiprocessing import Pool |
三、线程与进程的关系与区别
- 线程是执行的指令集,进程是资源的集合;
- 线程的启动速度要比进程的启动速度要快;
- 两个线程的执行速度是一样的;
- 进程与线程的运行速度是没有可比性的;
- 线程共享创建它的进程的内存空间,进程的内存是独立的。
- 两个线程共享的数据都是同一份数据,两个子进程的数据不是共享的,而且数据是独立的;
- 同一个进程的线程之间可以直接交流,同一个主进程的多个子进程之间是不可以进行交流,如果两个进程之间需要通信,就必须要通过一个中间代理来实现;
- 一个新的线程很容易被创建,一个新的进程创建需要对父进程进行一次克隆
- 一个线程可以控制和操作同一个进程里的其他线程,线程与线程之间没有隶属关系,但是进程只能操作子进程
- 改变主线程,有可能会影响到其他线程的行为,但是对于父进程的修改是不会影响子进程;